How Far Is AI from Replacing Designers? A Conversation About Text-to-Design
By Dr Zhi 'Albert' Li
Introduction
In recent years, large language models and diffusion models have advanced at remarkable speed, and "generating 3D models from text" is no longer science fiction. From DreamFusion and Shap-E to Hunyuan3D, Tripo, and Meshy, Text-to-3D systems have already achieved striking visual results.
At the same time, another line of work, Text-to-CAD, has been gaining momentum in academia. Its goal is to generate editable parametric CAD models directly from natural language.
While following this area, I have noticed something worth discussing: the current evaluation setup for Text-to-CAD looks surprisingly similar to the evaluation setup for Text-to-3D. In both cases, generation quality is judged mainly through geometric similarity. But design, especially engineering design, derives its value from function rather than form alone. That makes me want to sort out the difference between these two technical directions, review the current research landscape, and think about whether the way we evaluate these systems is actually aligned with what design is.
The Fundamental Difference Between Text-to-3D and Text-to-CAD
To understand the difference between the two directions, we first need to understand what they produce.
Text-to-3D Generates "Shape"
Typical Text-to-3D systems include DreamFusion (Poole et al., 2022), Magic3D (Lin et al., 2023), Point-E, and Shap-E (Nichol and Jun et al., 2022-2023). Their outputs are usually meshes, point clouds, NeRFs, or Gaussian splats. What all of these representations have in common is simple: they produce a static geometry that records what an object looks like.
This class of methods is already quite mature visually. For game assets, film concept art, and other applications where visual appearance is the goal, the value is obvious. But from the point of view of engineering design, these outputs are still insufficient. They typically lack parametric history, constraints, feature trees, material properties, and tolerance information, which means they are difficult to edit and hard to use directly in manufacturing workflows.
Figure 1. Current text-to-3D systems can already produce visually impressive results. Image source: Meshy website screenshot.
Text-to-CAD Should Generate "Process"
Text-to-CAD aims to produce parametric CAD models. A CAD model is not just a shape. It is closer to a program: an ordered series of modeling steps such as sketching, extrusion, filleting, and boolean operations, tied together by constraints and dependencies. In software like SolidWorks or Fusion 360, engineers are effectively writing that program.
That means a CAD model records not just what something looks like, but how it was designed. That editable, parametric nature is what allows a CAD model to be revised, optimised, and manufactured. An engineer can change one dimension and the entire model updates. With a mesh or point cloud, meaningful revision often means starting over.

Figure 2. CAD design. Image source: crennovations.com.
If you ask Text-to-3D and Text-to-CAD to generate a computer mouse, the difference can be summarised in one sentence:
Text-to-3D generates a 3D model that looks like a mouse.
Text-to-CAD should generate a manufacturable, assemblable, functional mouse design.
Figure 3. A mouse is a functional product assembled from multiple components. Image source: Free3D.
Figure 4. A mouse design generated by Meshy. Image source: Meshy website, prompt by nic.-madewell.
Current Research Progress in Text-to-CAD
The current Text-to-CAD literature can be roughly grouped into several technical routes.
1. Treating CAD Construction Sequences as a Language
These methods represent a CAD model as a sequence of operations, such as sketching and extrusion, and then model that sequence in a way similar to natural language.
DeepCAD (Wu et al., ICCV 2021) is a foundational example. It encodes CAD models as "sketch plus extrusion" sequences and uses a Transformer-based variational autoencoder to learn their distribution, sampling new CAD models from that space. Its training data comes from the ABC dataset (Koch et al., 2019), which contains about 180,000 CAD sequences. However, DeepCAD is unconditional and does not support text prompts.
SkexGen (Xu et al., ICML 2022) improves on this by disentangling topology, geometry, and extrusion parameters, modeling them separately and then recombining them, which improves both quality and diversity.
Text2CAD (Khan et al., 2024) introduces text conditioning. It uses a large-language-model-style architecture to autoregressively generate CAD construction sequences from natural language descriptions. Its text annotations are obtained by using a vision-language model to caption rendered images of existing CAD models.

Figure 5. A comparison of text-to-3D effects. Image source: the original Text2CAD paper.
2. Using Large Language Models to Generate CAD Code
Another route treats CAD modeling as a code generation problem. Since CAD construction sequences are effectively programs, one can ask a language model to generate CAD scripts directly in languages such as OpenSCAD or CadQuery.
CAD-GPT (2024) follows this idea, relying on fine-tuning or prompt engineering to produce valid CAD programs. The advantage is that it can reuse general code-generation abilities already present in language models. The limitation is that the quality of the output depends heavily on how well the model understands CAD-specific domain knowledge.
3. Applying Diffusion Models to Structured Representations
Work such as BrepGen (Xu et al., 2024) applies diffusion directly to B-rep representations. Instead of modeling a construction sequence, it represents CAD as a structured set of faces, edges, and vertices, then learns to denoise and generate that structured geometry.
4. Unifying B-Rep Geometry and Construction Sequences
More recently, Pointer-CAD (Qi et al., CVPR 2026) proposed an especially interesting direction. Earlier sequence-based methods relied on discretised numerical values to describe geometric parameters, which created two major problems: they could not easily refer to a specific existing edge or face, and numerical discretisation introduced quantisation errors that could break topological continuity.
Pointer-CAD introduces a pointer-based entity-selection mechanism. Each command is decomposed into labels, values, and pointers. When an operation needs to select a particular edge or face, the model predicts a pointer vector and matches it against candidate geometric entities rather than regressing explicit coordinates. At the same time, generation is performed step by step, with the current B-rep geometry provided as conditioning input through a graph neural network that encodes face adjacency.
The significance of this approach is that it makes operations such as filleting and chamfering much more realistic to generate, because those operations require the model to identify specific geometric entities. The work also introduces the Recap-OmniCAD+ dataset, which contains roughly 575,000 text-annotated CAD models, a major increase in scale.
Shared Limitations Across Current Research
Despite their different technical routes, current Text-to-CAD systems still share several limitations:
- The operation vocabulary is extremely narrow. Most work supports only "sketch plus extrusion." In real engineering, common operations also include fillets, chamfers, shells, sweeps, lofts, revolves, arrays, mirrors, and booleans.
- They generate only single parts. Real engineering often involves assemblies, with mating constraints, interference checking, and kinematic relationships.
- The datasets are still too simple. ABC and Fusion 360 Gallery are valuable, but the models are generally much simpler than production-grade CAD in automotive, aerospace, or consumer electronics.
Thinking About Evaluation: What Does Chamfer Distance Really Measure?
The discussion above concerns technical limitations. I also want to talk about something deeper: whether the current evaluation methods used in Text-to-CAD actually fit the thing they claim to measure.
Starting with Chamfer Distance
Chamfer Distance is the most common metric in current Text-to-CAD work. It is computed by sampling both the generated model and the reference model as point clouds, then averaging nearest-neighbour distances between the two sets. The lower the value, the closer the shapes are geometrically.
Other common metrics, such as Coverage (COV) and Minimum Matching Distance (MMD), compare distributions of generated and reference samples. CLIP Score measures semantic alignment between rendered images and text prompts.
What all of these metrics have in common is this: they answer some variation of the same question, namely whether the generated model looks like the reference model or the prompt.
That is important, but Chamfer Distance remains purely geometric. It does not care whether a hole is through or blind, whether a face meets tolerance requirements, or whether two gears would mesh correctly. As long as the sampled points are spatially close, the score can still be good. In other words, Chamfer Distance measures geometric similarity, not functional correctness.
That may be acceptable for Text-to-3D, whose typical applications live in games, film, and virtual environments where appearance is the primary goal. But for Text-to-CAD, if we truly want to support engineering design, then "does it look right?" may not be the most important question.
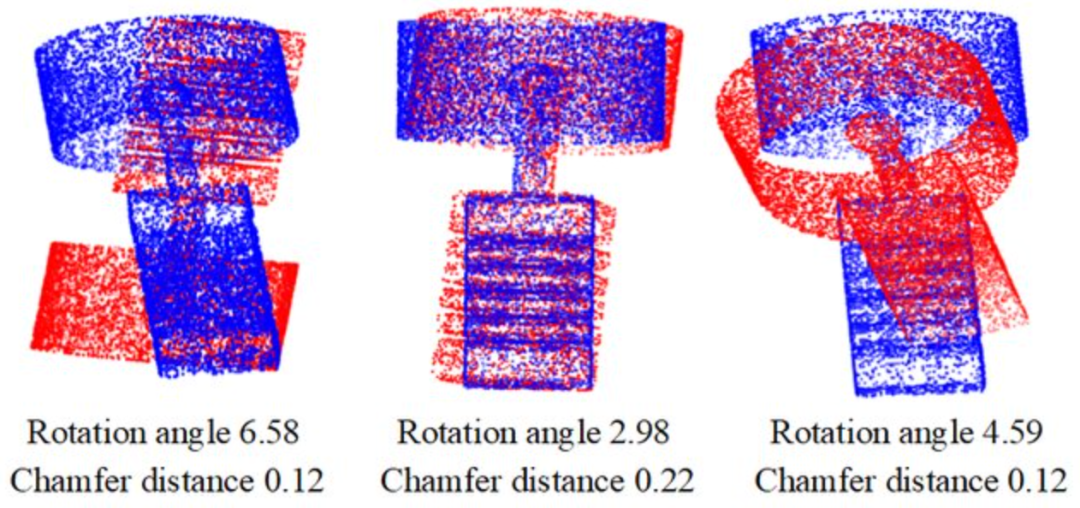
Figure 6. A visualisation of Chamfer Distance. Image source: "Self-Supervised Point Cloud Registration with Deep Versatile Descriptors."
The Role of Function in Design
In engineering, the value of a part is defined first by its function. A bracket must remain structurally sound under load. A gear must have the right involute tooth profile and module to mesh properly. A housing must satisfy thermal requirements, fit internal components, and remain manufacturable.
As far as I can tell, current Text-to-CAD evaluation pipelines still do not explicitly include several dimensions that matter deeply in real design:
- Structural performance: how the generated part behaves under load
- Kinematic correctness: whether a mechanism moves as intended
- Manufacturability: whether draft angles, wall thickness, and fabrication constraints are respected
- Tolerance and fit: whether the model contains the information needed for correct assembly
- Standards compliance: whether features such as threads and keyways follow industrial standards
That leaves open a troubling possibility: a generated model may score well on Chamfer Distance because it looks very similar to a gear, while still failing as an actual gear in practice. The current evaluation setup does not really separate "shape resemblance" from "usable design."
Metrics Shape Research Directions
I do not think current research is wrong. On the contrary, much of it has made valuable technical progress. But evaluation metrics shape research agendas. If a field rewards geometric similarity above all else, then research will naturally optimise for geometric similarity.
That is understandable. But if we want Text-to-CAD to become genuinely useful for engineering design, then the evaluation system probably needs to be extended.
From another angle, if Text-to-CAD and Text-to-3D are both judged mainly by geometric similarity, then the distinctive value of Text-to-CAD becomes harder to articulate. Text-to-3D is already very strong at producing visually convincing shapes, and it does so without the constraints of parametric construction sequences. If Text-to-CAD is genuinely different, then that difference likely lies in its ability to carry functional information, satisfy manufacturing constraints, and support parametric editing. Those are exactly the aspects the current metric stack does not yet capture well.
Conclusion
Text-to-3D and Text-to-CAD may look similar on the surface because both generate 3D content from text. But they aim at fundamentally different applications. Text-to-3D prioritises visual realism. Text-to-CAD, if it truly wants to serve engineering design, has to deliver functional value as well.
Current Text-to-CAD research has made meaningful progress, and the different technical paths are all worth taking seriously. But the widespread use of geometry-based metrics such as Chamfer Distance still means that the field is largely measuring "Does it look similar?" while design is often about "Does it actually work?"
That gap deserves more discussion.
References
Poole, B., Jain, A., Barron, J.T. and Mildenhall, B., 2022. DreamFusion: Text-to-3D using 2D Diffusion. arXiv preprint arXiv:2209.14988.
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y. and Lin, T.Y., 2023. Magic3D: High-Resolution Text-to-3D Content Creation. CVPR 2023.
Nichol, A., Jun, H., Dhariwal, P., Mishkin, P. and Chen, M., 2022. Point-E: A System for Generating 3D Point Clouds from Complex Prompts. arXiv preprint arXiv:2212.08751.
Jun, H. and Nichol, A., 2023. Shap-E: Generating Conditional 3D Implicit Functions. arXiv preprint arXiv:2305.02463.
Wu, R., Xiao, C. and Zheng, C., 2021. DeepCAD: A Deep Generative Network for Computer-Aided Design Models. ICCV 2021.
Xu, X., Willis, K.D., Lambourne, J.G., Cheng, C.Y., Jayaraman, P.K. and Furukawa, Y., 2022. SkexGen: Autoregressive Generation of CAD Construction Sequences with Disentangled Codebooks. ICML 2022.
Khan, M.A., Ud Din, S. and Pagani, A., 2024. Text2CAD: Generating Sequential CAD Models from Beginner-to-Expert Level Text Prompts. NeurIPS 2024.
Xu, X., Lambourne, J.G., Jayaraman, P.K. and Willis, K.D., 2024. BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry. SIGGRAPH 2024.
Qi, D., Wang, C., Xu, J., Chu, T., Zhao, Z., Liu, W., Ding, W., Ma, Y. and Gao, S., 2026. Pointer-CAD: Unifying B-Rep and Command Sequences via Pointer-based Edges & Faces Selection. CVPR 2026.
Koch, S., Matveev, A., Jiang, Z., Williams, F., Artemov, A., Burnaev, E., Alexa, M., Zorin, D. and Panozzo, D., 2019. ABC: A Big CAD Model Dataset for Geometric Deep Learning. CVPR 2019.
Willis, K.D., Pu, Y., Luo, J., Chu, H., Du, T., Lambourne, J.G., Solar-Lezama, A. and Matusik, W., 2021. Fusion 360 Gallery: A Dataset and Environment for Programmatic CAD Construction from Human Design Sequences. ACM Transactions on Graphics, 40(4).